No ranking without indexing. In this blog post, I answer 10 basic questions about Google indexing that are relevant for every SEO.
#1 What is the Google Index?
The name “index” already tells it – it has the meaning “register” or “directory”. Indexing is simply said: The storage of a URL in the Google database. This database includes all content that can be found via search.
Indexing is the basis to be found via Google search. If the content you want to be found with is not in the big Google index, you simply do not exist in the SERPS. In short: Without indexing no ranking.
Before indexing, Google must first find the pages, this is done via the process of crawling: The Googlebot follows internal and external links.
In the first processing loop, the HTML document is downloaded and the status codes and meta tags are checked. For example, if your page is equipped with the Noindex tag, the process stops here, because this is your instruction: “Please do not index this page”.
During rendering, Google reads the entire document with all its content. Among the items that are processed are these:
- Visualization of the page
- Reading structured data
- JavaScript is executed
- Checking for duplicate content and many more.
When this process is complete and your URL has passed the “test”, it can be included in the Google index and can in principle be found via Google search. Why am I writing this in the subjunctive? Because these steps are the prerequisite for indexing, but not a guarantee.
Important: Indexing does not mean ranking and has nothing to do with ranking factors – but only says whether a URL is stored in the Google database.
#2 Do all pages have to be in the Google index?
No. Correct is: All your important and relevant pages should be in the index, which fulfills the search interest of users. Pages that do not meet this requirement should not be in the Google index. This includes, for example, pages with identical content, but also pages that belong to user accounts and are only accessible after login.
However, it is also true that the larger your website, the greater the importance of indexing control. Control means that you tell Google specifically which pages deserve a place in the index – and above all: which do not.
If the crawler has to work its way through hundreds of thousands of unimportant URLs until it gets to the important pages, your crawl budget is quickly used up and relevant pages remain undiscovered – and thus without a chance of being indexed.
#3 How do I check if a certain URL is indexed?
There are two ways to check if a certain page has been indexed by Google.
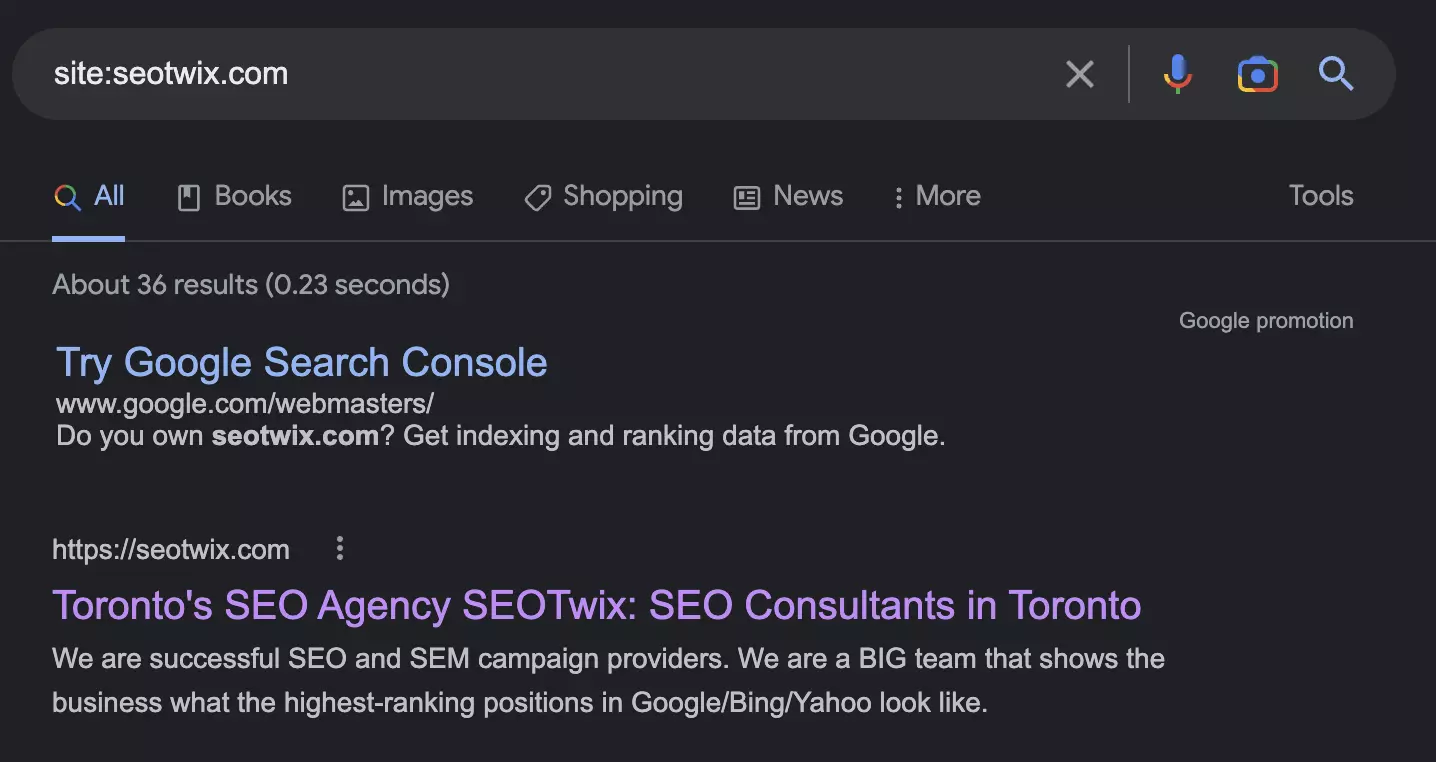
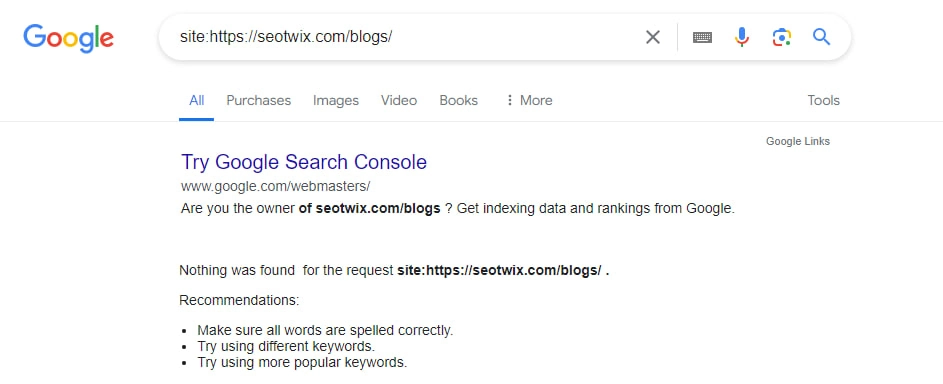
Checking via Site Search
The easiest way is via Google search: just enter the URL of the landing page with the search operator “site:”. If the page is indexed, it will show up as a search result.
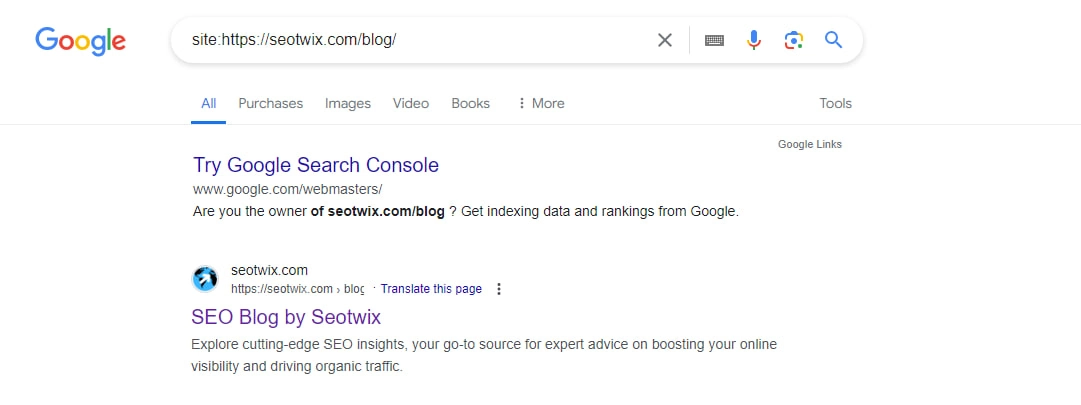
If it is not in the index, the search will not return any results. You can also use this method to check whether certain content sections of your page are in the index.
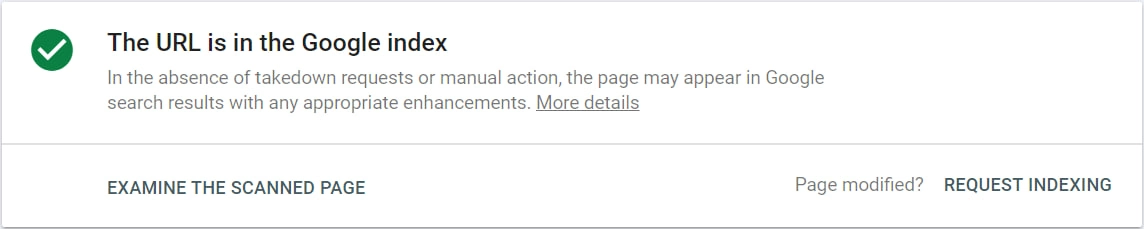
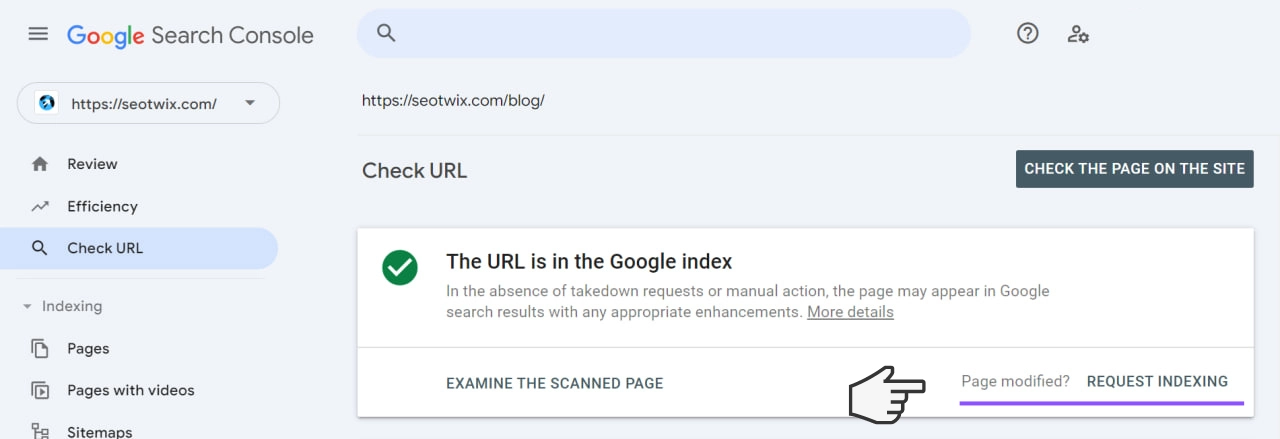
Checking via the URL check tool of the Google Search Console
Enter the URL into the URL check tool of the Google Search Console. You can find the tool at the top of the page:

The checked URL is indexed – so far, so good.
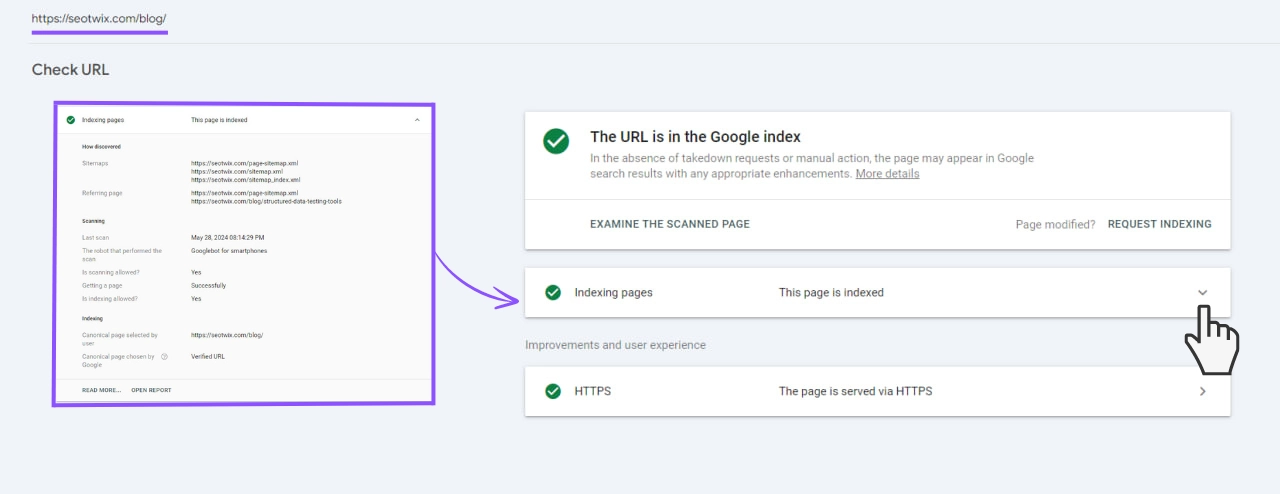
In addition, the URL check tool gives you further answers to the following questions:
- How did the Googlebot find the page (sitemap and/or links)?
- Is crawling basically allowed?
- When was the URL last crawled?
- Was the mobile version or the desktop version of the page crawled?
- Can the page be indexed?
- Which URL is the canonical one and does the canonical page selected by Google match the one you specified?
- What structured data is stored and is it technically error-free?
- Is the page secure, is it retrieved via HTTPS protocol?
#4 How do I check the status of my entire website?
The Google Search Console not only provides you with an overview of the indexed and non-indexed URLs of your website.
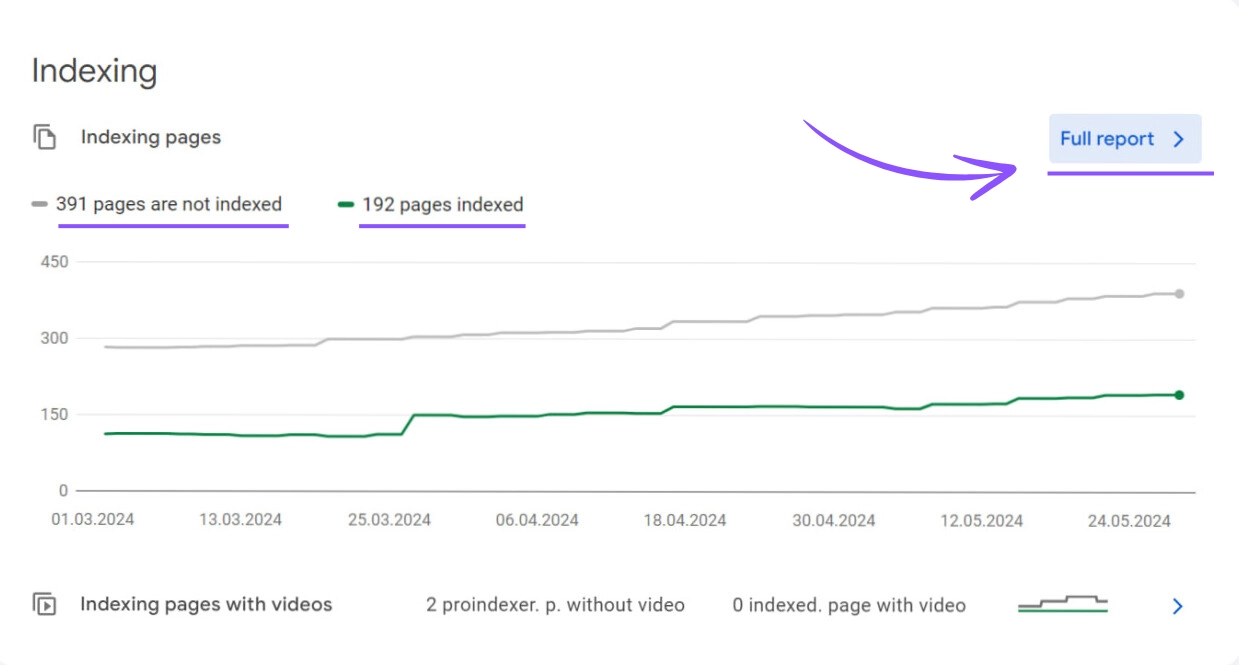
It also shows you possible reasons why pages were not included in the index:
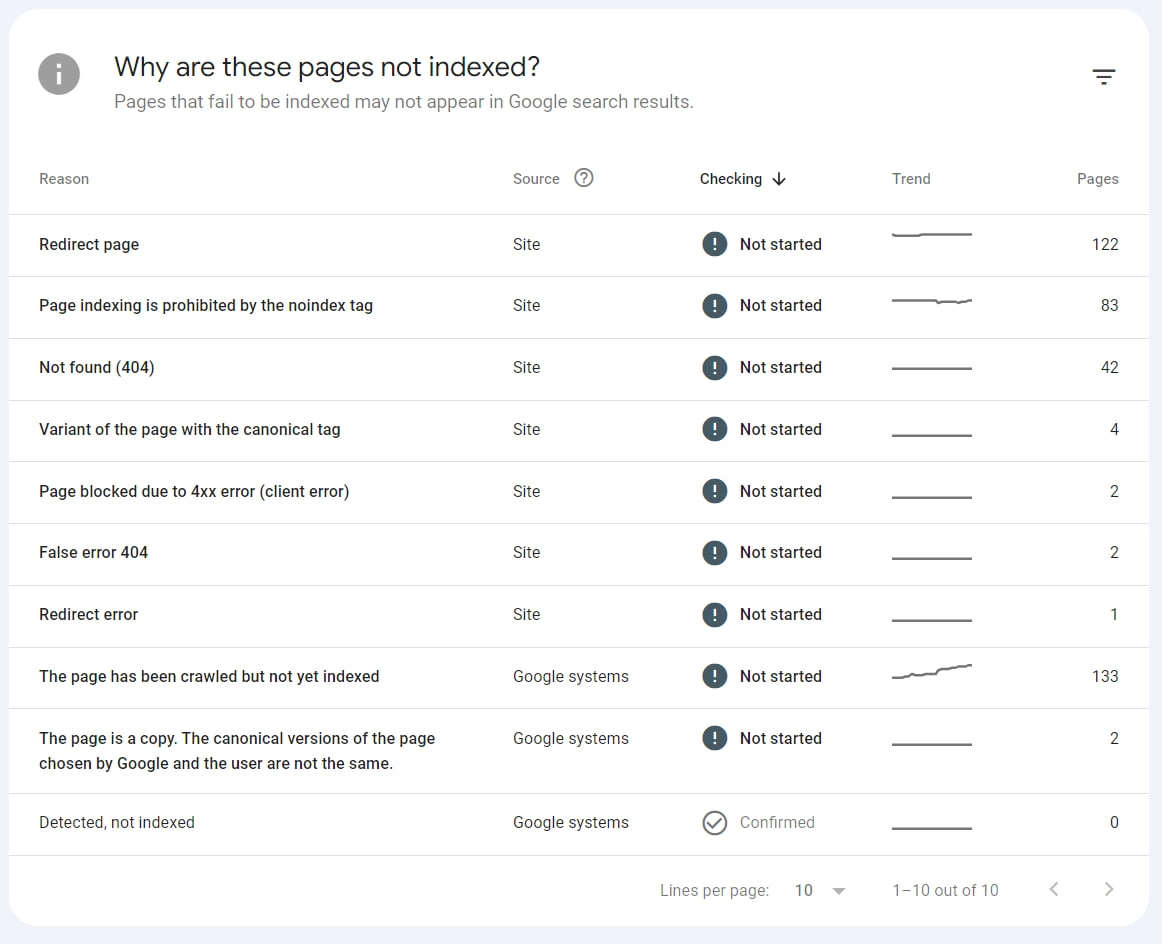
Reasons for non-indexing are for example:
- Duplicate content, URLs with identical content
- forwarded URLs
- canonicalized URLs
In addition, in the report, you will find information about pages that the Googlebot has crawled but not indexed or found and not even crawled.
The Google Search Console API for the Screaming Frog is a second way to check the indexing status.
Let’s say you want to check 150 of your most important pages for their status with Google. With the URL check tool, this should take quite a long time, and the coverage report will only help you to a limited extent.
In this case, you will gain more efficient insights if you crawl the URLs in list mode with the Screaming Frog and the API.
This report provides you with the same bundled information as the Google Search Console, but clearly bundled by URL:
- Clicks, Impressions and Position
- Summary of the status
- Coverage information: for what reason is a URL not indexed?
- Time of last crawl / days since the last crawl
- How was crawled – via mobile or desktop agent?
- Was the page retrieval successful?
- Is indexing allowed in principle?
- Canonical page is chosen by the user and the canonical page is determined by Google
- Assessment and errors on mobile usability
- Assessment and errors on AMP version
- Information about the types of structured data & errors found.
#5 How do I request a page to be indexed?
If you have revised a page or want to trigger crawling and indexing of new content, you request it in the Google Search Console review tool.
Attention: You can trigger the crawling, unfortunately, this does not automatically mean that the bot will come over immediately.
#6 How long does it take until my page is indexed?
How much time passes until your new or revised content is indexed cannot be predicted. Google itself makes very squishy statements about this:
“After you put a new page online, it may take some time before it is crawled. Indexing usually takes even longer. The total time can range from a day or two to a few weeks.“
To avoid delaying crawling and indexing, you should make it as easy as possible for the Googlebot to crawl and rank:
- Avoid basic technical problems like server errors, very slow loading times and soft 404 errors. These have a negative impact on your crawl budget and reduce the capacity for crawling important pages.
- Show the Googlebot the way: Make sure that you clearly communicate which pages should be indexed and which should not.
- Use the meta tag “Noindex” and “Index” for this, mark URL duplicates with the canonical tag and configure the txt.
- Provide one or more segmented sitemaps. Use the “lastmod” tag to alert Google to content updates with the sitemap.
- Create unique and relevant content for your users.
- Make sure that important pages are well linked internally and that the click path length is as short as possible.
#7 Can I speed up Google indexing?
You can’t force Google to index your pages directly and immediately. What you can do for very important new or updated content: Manually request indexing via the review tool.
Although Google officially says that submitting a URL multiple times does not speed up the crawl and indexing process, we have had different experiences. Resubmitting and resubmitting multiple times can definitely speed up the indexing process.
Good to know: The number of indexing requests per day in Google Search Console is limited to 10 URLs in 24 hours.
#8 Why isn’t Google indexing my site?
Google does not index your content? There are many reasons for this, you should check and exclude these 4 in any case:
Reason 1: You have forbidden it.
Check if the page has the meta tag “Noindex” or is excluded from crawling in robots.txt. If everything is OK here, check whether the URL refers to another URL via a canonical link.
Reason 2: You provide ambiguous or no information.
If you don’t give Google any hints about your wishes in the form of canonicals, robots.txt and “noindex” tags for a large website, the bot will crawl many URLs and classify them itself. If there are many irrelevant pages, they will quickly eat up your crawl budget.
Incorrect and contradictory information on your page can also lead to pages not being included in the Google index. An example: A URL A is sent in the sitemap, but refers via Canonical to another URL B. This is not in the sitemap. On the one hand, it is difficult for Google to find URL B and crawl it. On the other hand, due to the errors, URL B (the important URL) may not be indexed. Besides canonicals, wrong hreflang statements in combination with canonicals are common sources of errors. Ergo: Make sure that Google can crawl and index only relevant URLs if possible.
Reason 3: The page is difficult for Google to find.
If the URL in question has no incoming internal or external links, then it is called an “orphan URL”. Since crawling takes place via hyperlinks, this page cannot be found by the Googlebot – and thus cannot be indexed.
In this case, you should:
- ensure a better internal linking of traffic-strong sides.
- include the page in the sitemap.
- make sure that your internal links always have the “follow” attribute.
Reason 4: The page has low quality.
Check if the content of the page meets the qualitative requirements, has relevance and offers a good experience for the users. (Keyword loading time and navigation).
#9 Why is my page indexed even though I have forbidden it?
Sometimes it happens that pages are indexed although they are actually excluded from crawling via robots.txt. This is the case when a page is already in the Google index and you exclude it only afterwards in the robots.txt. Now Google can no longer crawl because you have forbidden this – but the pages are still in the index.
You can avoid this collision by checking if these pages are already indexed before excluding certain URLs. If so, you should ask for what reasons they are indexed and exclude that they have content relevance.
URLs that are indexed despite being blocked are usually not a critical problem: over time, Google understands what you are about – and the URLs disappear from the index.
#10 How do I remove a page from the Google Index?
To permanently remove pages from the Google index, you must either exclude them from crawling or set them to “Noindex” – all other measures are either not permanent or not mandatory for Google.
If you want to remove a URL from the index temporarily, you can submit a request in the Google Search Console.
You have two options:
- Either exclude the URL from the search results for 6 months.
- Delete the cached information about the snippet and the page until the next crawl.
With this function you don’t stop crawling, you just make sure that this page doesn’t appear in the search results for about 6 months. I personally have never used this function, but it can be useful in certain cases. Among other things, if you need to quickly remove a result from the SERPS for legal reasons.
Conclusion
In order for Google to reliably index your important pages, these points are essential:
- Consider crawling and Google indexing as an important basis – both are mandatory requirements for your rankings.
- Provide clear and technically correct information about crawling and indexing on your website. This way the bot will find the right way in a way that is easy on the crawl budget. The bigger your website, the more important this is.
- Create unique, relevant and user-centric content – and focus on the success of this in terms of indexation control and monitoring.
To ensure that your website fully complies with these guidelines and achieves optimal performance in search engine rankings, consider enlisting the expertise of our SEO specialist. Our expert will provide personalized strategies tailored to your website’s needs, ensuring efficient crawling and indexing by Google. They will also help you create and optimize content that not only engages users but also enhances your site’s visibility and ranking. Investing in professional SEO services is a strategic step towards sustainable online success.