

In this post, I’m going to explain to you a basic SEO topic that is nonetheless important: http status codes. If you’re on the web, you’ve probably come across these responses before. What http status codes are, what 200, 301, 302, 404, 410 & Co. are all about, you will learn in this blog post.
What are HTTP Status Codes?
The HTTP status code is always the server’s first response to a request from a client (e.g. a browser). Through the status code, the server tells the client whether its request was successful. If the response is not successful (200), it uses another status code to provide information about what is wrong (e.g. page not found) or how the request can be made successful (e.g. via a redirect). But let’s start with the explanation of the different technical terms:
What is a Client?
A client is a program on your PC or on the end device of a network with which the server “talks” and exchanges information. This includes, for example, web browsers such as Chrome, Mozilla Firefox or Safari, which communicate with web servers and receive the information from them to display the pages. But there are also, for example, e-mail clients that retrieve or send mail from e-mail servers.
What is a Server?
The term “server” can be understood to mean two different things:
Server as hardware: this is a network computer that provides resources for other computers. It is often referred to as a “host”. Software servers are also installed on the hardware server. Roughly speaking, it is therefore the physical storage location.
Server as a software-based server: This is a program whose special service can be used by other programs (= clients). The basis for this is the client-server model. Besides web servers, there are other servers, for example file servers (FTP servers, among others), e-mail servers (IMAP/POP or SMTP servers), printer servers, database servers (e.g. MySQL), VPN servers (encrypted, private connections to a network) and proxy servers, as well as a few others that I won’t list all here.
The Five Classes of HTTP Status odes
The http status codes can be divided into five classes:
1xx: The server has received the request and communication with the client is in progress. This status code instructs the client to wait for the final information.
2xx: This group of status codes indicates that the request was not only received, but also successful.
3xx: The client’s request has reached the server, but another step is needed by the client to complete the request successfully.
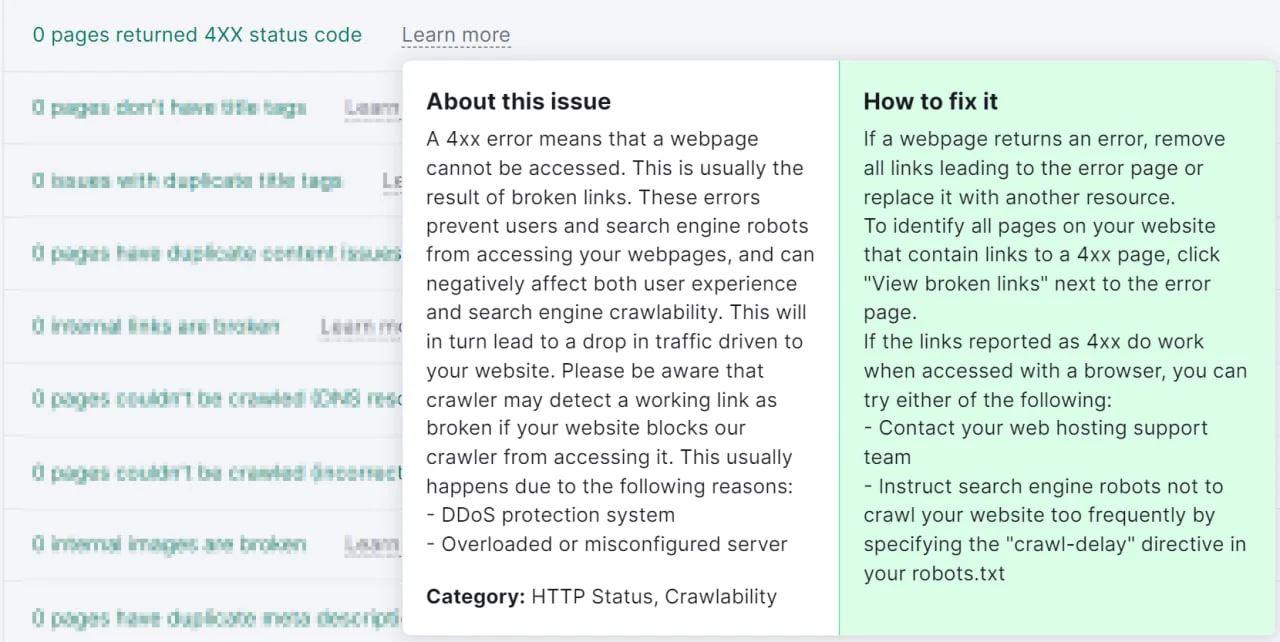
4xx: The request was incorrect – the error is on the client’s side (for example, resources not found or missing authorization).
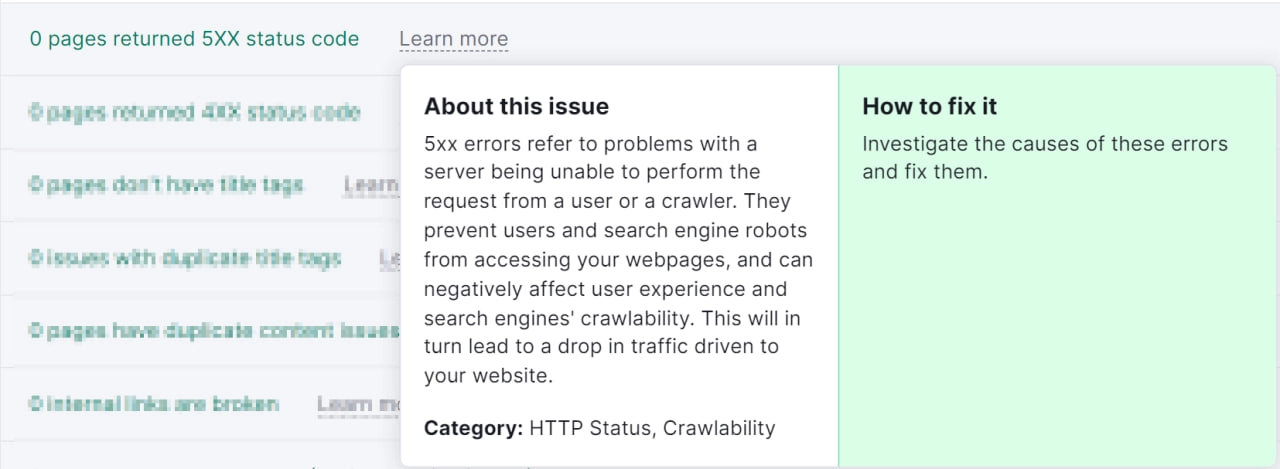
5xx: The request was incorrect, but the error is on the server side (for example, overload or maintenance).
Influence of The Status Codes on Your SEO Performance
For all 2xx http status codes, Google considers indexing. However, if an error is likely and, for example, a blank page appears, then Search Console will display a soft 404 error. Here you should make sure that this type of error is corrected.
The 3xx status codes are all redirects. In this case, the Googlebot follows up to 10 redirect hops, according to Google Developers. However, if the bot does not encounter any content there, a redirect error is displayed.
Here’s what a redirect chain looks like: URL A > URL B > URL C
This is what a redirect loop looks like: URL A > URL B > URL A > URL B …
Also important: Each redirect costs about 0.2 seconds of loading time. If you have unnecessary redirect chains, this will increase the loading time, which is bad for your SEO performance.
For Google indexing, 4xx status codes are not taken into account. URLs that have already been indexed can be kicked out of the index if they continue to return a 4xx response. This content is ignored by the Googlebot.
Status codes with 5xx, on the other hand, temporarily slow down the crawling of bots like the Googlebot. If a URL is already indexed, it remains in the index. If the 5xx response persists, they will ultimately be removed from the index as well.
Influence of The Status Codes on Your SEO Performance
Not all status codes are relevant for SEO and influence your ranking. Therefore, it is important to know which status codes you should keep an eye on. To find out which status codes your pages are giving out, you can crawl the page with Screaming Frog for example. Google has documented the most important http status codes in detail in a post in Google Search Central.
Status Code 200: OK
At best, most of your pages will return the http status code 200. This is the rule: the client’s request was successful, it was accepted by the server and the requested resource is available. It is sent to the client and your requested page is displayed. Make sure that not just any URL – even fantasy URLs – output an http status 200, otherwise you will have the soft-404 errors mentioned above.
Status code 301: permanent redirect
The http status code 301 is the permanent redirect. It gives the answer to the server that the resource can be found permanently at another address. Search engine bots and visitors are redirected directly to the new page. The advantage of 301-forwards is that they pass on the link power and the new URL is indexed.
You can find out if Google has already accepted your 301 forwarding by using the URL check tool of the Google Search Console.
A typical use case in SEO is also, for example, the merging of two very similar pages. With a 301 forwarding, the rankings of the “old” URL are usually passed on to the “new” address – as long as the content matches:
You can check the success of the ranking transfer wonderfully in the Google Search Console:
Compare the ranking of the old URL with the new URL by using the filters of the GSC.
Status Code 302: Temporary Redirect
While the 301 status code says that a resource has now been moved permanently, the 302 http status code says that the resource has only been moved temporarily. This means that the content of the page can be found again under the old URL in the future and it will be preserved. By the way, according to Google, Pagerank passes on all types of redirects – both 302 and 301. The only difference is that with a 302 redirect, the destination URL is not cached.
Status Code 401: Unauthorized
The http status code 401 belongs to the incorrect responses. This status code indicates that the client’s request was rejected by the server due to missing or invalid authentication.
Status Code 403: Forbidden
Similar to the 401 status code is the 403 http status code, which means “forbidden”. Here the server has understood the client’s request, but refuses to allow it. The access is permanently forbidden. This can be, for example, for pages that are protected with a password like accounts of e-commerce stores that require a login. This may have been a specific action of the webmaster, for example, that certain bots of tools or IP addresses are blocked, but it can also happen unconsciously, for example, if you have set an internal link to a (still blocked) directory of your website. It is especially dramatic if you accidentally lock out the Google Bot – this happened to one of our customers:
When calling up a page, the browser identifies itself with its “identifier”, the so-called
so-called “user agent”.
Normal browsers of users have a user agent like “Firefox” or “Chrome.
If the URLs of the project are called up with these user agents, the pages are displayed correctly.
Technically, this can be recognized by the fact that the HTTP status code 200 (“OK”) is returned.
Status Code 404: Not Found & Soft 404
The http status code 404 states that the requested resource cannot be found at the moment. An error page is displayed. Often this is because there are typos, links are set incorrectly or content has been deleted. This status code is basically not bad. The http status 404 belongs in a certain amount to a healthy page architecture.
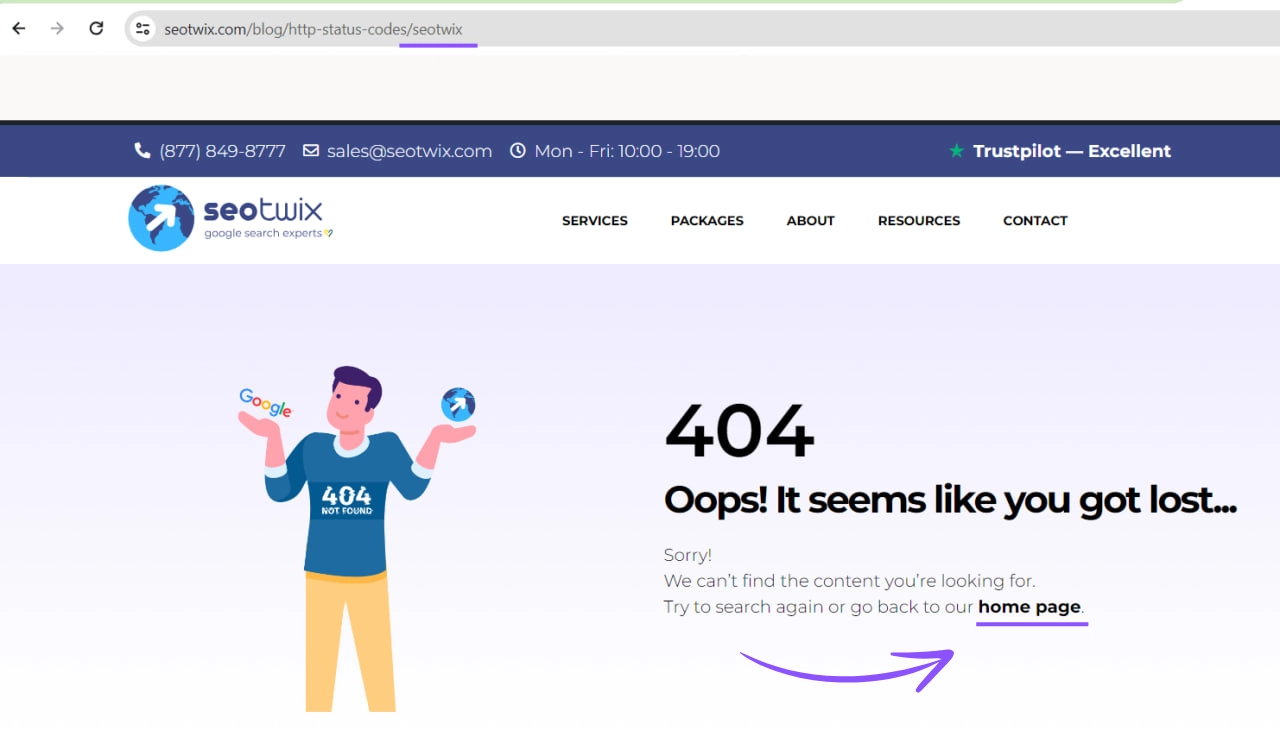
A well set up 404 error page that is played out can help users. What should be avoided are frequent 404 responses, especially for important pages. Therefore, there are both opportunities and risks for 404 status codes.
Soft 404 errors are websites that no longer display the requested content, but do not issue a 404 error. As a result, the status code 200 is issued incorrectly.
It is not good for users and search engines if content is searched for and the page does not output an error code, but content that does not match the search query. Google’s recommendation is to work with the 404 status code here. Additionally, the displayed error page can be optimized to keep users on the website.
Status Code 410: Gone
This http status code states that the resource can no longer be accessed because it has been permanently deleted.
If you are not sure whether the resource is only temporary or permanently gone, http status code 404 should be used.
Status code 500: Internal Server Error
The http status code 500 belongs to the server side codes and describes the Internal Server Error. The resource that the client has requested cannot be displayed due to the server error. A lot of server errors can fall under the 500 status code, so it is not very meaningful. Another reason why the 500 status code is output is incorrect entries in the .htaccess file.
Status Code 502 – Bad Gateway
This status code means that the communication between the client and the server is not working. The reason for this can be on the side of the user, the Internet provider or the hosting provider. The users of your website will not be able to access the content of the requested page. If the error occurs more often, users will not come back. These negative user signals in combination with the http status code can lead to ranking losses and even removal from the index in the long run.
Status Code 503: Service Unavailable
Similar to this is the status code 503, which states that the server is temporarily unavailable. This http status code is used, for example, when the server is overloaded or undergoing maintenance. Make sure that this status code is only temporary, so that your site does not lose rankings or fly out of the index.
Status Code 418 – I’m a Teapot!
Probably the most important status code concerning SEO is the http status code 418 (attention, irony!). This response code was introduced by Requests for Comments in 1998 and says: “I’m a teapot!””. It is part of the series of April Fool’s jokes. In 2014, Google rediscovered it and included it:
The 418 status code with the teapot is, of course, not SEO relevant. Google does treat it like a 200 status code, but we still strongly advise you not to use it.
Other (Less Known) Status Codes
The status codes mentioned in this section are rather unknown. Two proprietary status codes are mentioned and explained here.
Status Code 906
If an error occurred during transmission of the request from the client to the remote server, then status code 906 is issued. The request must be sent again by the client.
Status Code 950
The 950 http status code also belongs to the proprietary status codes. If this has been issued, an error has occurred in the interpretation of an administrator request from the client. As with status code 906, the request usually needs to be resent.
Checking The HTTP Status Code & Special Cases
To get an overview of your site, you should crawl it regularly. This way you can detect and fix errors in your http status codes early.
Have you ever had the case that the robots.txt file gives a server error for more than 30 days? This can happen. This is how you should deal with it: If a server error status code has already been returned by the robots.txt file for more than 30 days, Google will use the last saved copy of the robots.txt file that is in the cache. If this is no longer available, Google assumes that there are no crawling restrictions. You can read more information about this at Google Developers.
Final thoughts
After reading my blog post, you are now well informed about HTTP status codes and their use in SEO. Understanding and correctly implementing these codes is crucial for maintaining a healthy website and improving its search engine rankings. If you find this aspect of SEO challenging or need expert guidance to optimize your website’s performance further, consider leveraging the expertise of our SEO specialist. Our expert can provide tailored strategies and hands-on support to ensure your website adheres to best practices, maximizes visibility, and drives organic traffic effectively. Don’t hesitate to reach out for a consultation and take your website’s SEO to the next level.


