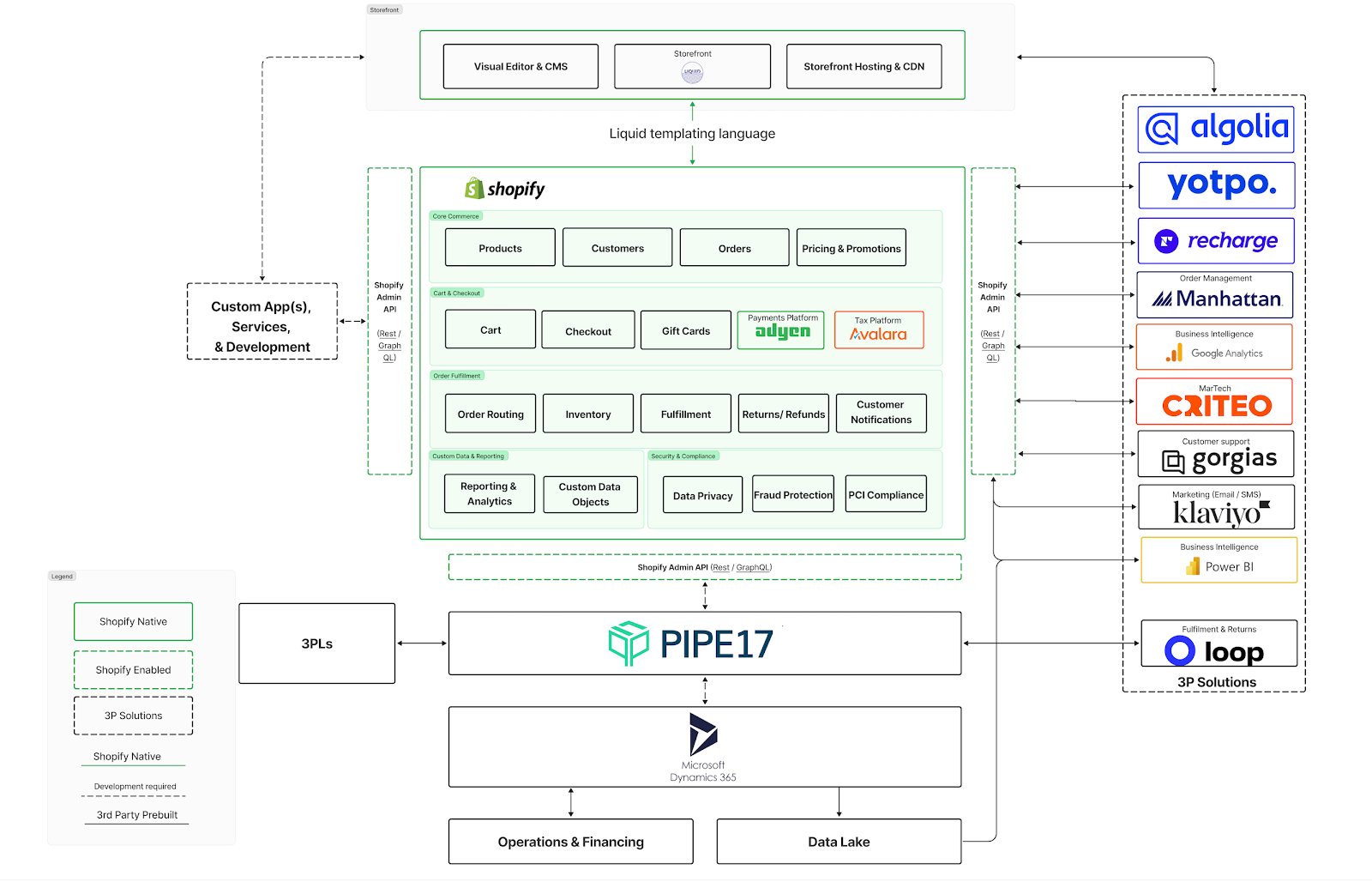
The Canonical Tag (meta tag) – also known as the canonical link attribute – is a tool designed to handle duplicate content by consolidating several identical pieces of content into one. It helps avoid the pitfalls associated with duplicate content issues. In this blog post, I’ll explain exactly how the canonical tag works, when you should use canonical links, and cover the most common canonical mistakes.
What is the Canonical Tag?
Canonical tags help you control the ranking URL of your page if you have identical content across different web pages. This is often the case when the content is displayed on several URLs.
Technically, the canonical tag is a link in the source code of a page. The link of the duplicates points to the original URL (known as the canonical URL). This marks it as the URL you want to prefer in the index. The canonical URL also has a canonical tag that points to itself; this is referred to as a self-referencing canonical tag.
Why is the Canonical Tag important for SEO?
If you have several identical or very similar pieces of content on your website, Google cannot always clearly recognize which URL is relevant and should be ranked.
Examples of identical content include URLs with and without parameters or different formats like print or PDF versions of an HTML page.
Instead of choosing your preferred page, it can happen that Google:
- Index all versions, resulting in duplicate content in the Google index. This can cause all versions to rank poorly compared to a single preferred version.
- One of the content ranks in top positions, but not your preferred one. For example, a PDF version of your landing page.
- Does not index any version, but excludes all of them from the index.
With the canonical tag, you signal to Google: “Here is the main version of the content. Please index it, transfer the signals of the duplicates to it, and rank only the original.” Thus, the canonical tag is a crucial SEO tool.
How to Implement Canonical Tags
Implementing canonical tags is a straightforward process. Here’s how you can do it:
1. Identify Duplicate Content
Begin by auditing your site to identify any duplicate content. Tools like Shemrush, Ahrefs, or Google Search Console can help you pinpoint these duplicates.

2. Determine the Canonical URL
Decide which version of the content should be the canonical URL. This will be the page you want search engines to prioritize.
3. Add the Canonical Tag
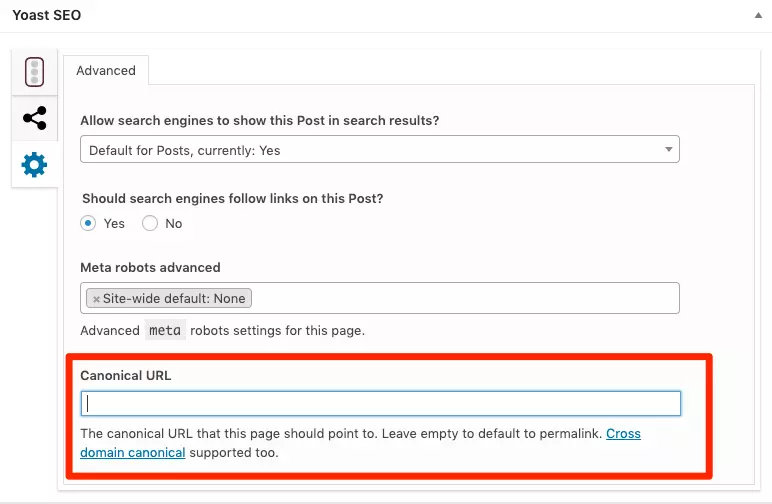
Insert the canonical tag into the HTML head section of each duplicate page. The tag should look like this:
<link rel="canonical" href="https://www.yourwebsite.com/preferred-page-url/">
4. Verify Implementation
After implementing the tags, use Google Search Console and other SEO tools to verify that the canonical tags are correctly recognized by search engines.
Best Practices for Canonical Tags
Use Absolute URLs
Always use absolute URLs in your canonical tags. This means including the full URL path rather than a relative path. Absolute URLs ensure clarity and prevent any misinterpretation by search engines.
Consistency is Key
Ensure that your canonical tags are consistent. If you’re pointing multiple pages to a single canonical URL, make sure each tag is correctly implemented without errors.
Regular Monitoring
Regularly monitor your site for duplicate content issues. SEO tools can help alert you to any problems, allowing you to address them promptly and maintain the integrity of your site’s SEO.
Canonical vs. Noindex
Understand the difference between using canonical tags and the noindex directive. While canonical tags help consolidate link equity to the preferred version, noindex tells search engines not to index a page at all. Use them appropriately based on your content strategy.
Canonical tags are a powerful yet often underutilized tool in the SEO arsenal. By preventing duplicate content issues, optimizing your crawl budget, and enhancing user experience, these tags play a vital role in ensuring your website’s SEO health. Implementing canonical tags may seem like a minor task, but the benefits it brings to your site’s visibility and performance are substantial. Embrace this small but mighty tool, and watch your SEO efforts yield better results.
To fully leverage the power of canonical tags and other advanced SEO strategies, consider consulting with our expert SEO team. Our professionals have the knowledge and experience to fine-tune your website’s SEO, ensuring every element is optimized for maximum impact. Let us help you achieve superior search engine rankings and drive more organic traffic to your site. Contact us today to elevate your SEO game and experience the difference expert guidance can make.